Upload Files to S3 and Load Redshift Etl

In that location are several ways to load data into Amazon Redshift. In this tutorial, we'll show you one method: how to copy JSON data from S3 to Amazon Redshift, where it will be converted to SQL format.
What is Amazon Redshift?
Amazon Redshift is a data warehouse that is known for its incredible speed. Redshift tin handle large volumes of data as well as database migrations.
(Infamously, Amazon came up with the proper noun Redshift in response to Oracle's database dominance. Oracle is informally known as "Big Red".)
Other methods for loading data to Redshift
Here are other methods for data loading into Redshift:
- Write a program and apply a JDBC or ODBC commuter.
- Paste SQL into Redshift.
- Write information to Redshift from Amazon Mucilage.
- Apply EMR.
- Re-create JSON, CSV, or other data from S3 to Redshift.
Now, onto the tutorial.
Getting started
We will upload two JSON files to S3. Download them from hither:
- Customers
- Orders
Notation the format of these files:
- JSON
- There is no comma between records.
- It is non a JSON assortment. Just JSON records one after some other.
The orders JSON file looks like this. It only has two records. Detect that there is no comma betwixt records.
{ "customernumber": "d5d5b72c-edd7-11ea-ab7a-0ec120e133fc", "ordernumber": "d5d5b72d-edd7-11ea-ab7a-0ec120e133fc", "comments": "syjizruunqxuaevyiaqx", "orderdate": "2020-09-03", "ordertype": "sale", "shipdate": "2020-09-16", "discount": 0.1965497953690316, "quantity": 29, "productnumber": "d5d5b72e-edd7-11ea-ab7a-0ec120e133fc" } { "customernumber": "d5d5b72f-edd7-11ea-ab7a-0ec120e133fc", "ordernumber": "d5d5b730-edd7-11ea-ab7a-0ec120e133fc", "comments": "uixjbivlhdtmaelfjlrn", "orderdate": "2020-09-03", "ordertype": "sale", "shipdate": "2020-09-16", "discount": 0.6820749537170963, "quantity": 42, "productnumber": "d5d5b731-edd7-11ea-ab7a-0ec120e133fc" } IAM part
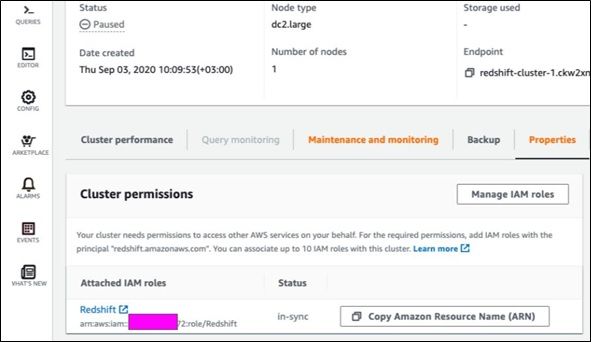
Y'all need to give a part to your Redshift cluster granting it permission to read S3. You don't requite it to an IAM user (that is, an Identity and Access Management user).
Attach it to a cluster—a Redshift cluster in a virtual auto where Amazon installs and starts Redshift for you.
Create the role in IAM and requite information technology some proper noun. I used Redshift. Give it the permission AmazonS3ReadOnlyAccess. so paste the ARN into the cluster. It volition look like this:
arn:aws:iam::xxxxxxxxx:role/Redshift
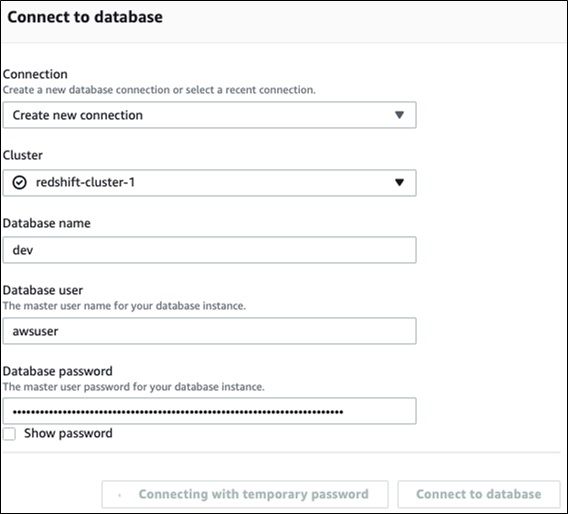
Create connexion to a database
Later on y'all beginning a Redshift cluster and you want to open the editor to enter SQL commands, y'all login as the awsuser user. The default database is dev. Use the selection connect with temporary password.
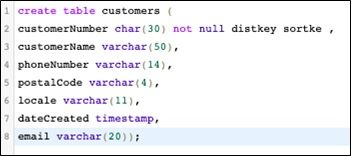
Create tables
Paste in these 2 SQL commands to create the customers and orders table in Redshift.
create tabular array customers ( customerNumber char(forty) not nothing distkey sortkey , customerName varchar(fifty), phoneNumber varchar(fourteen), postalCode varchar(4), locale varchar(11), dateCreated timestamp, email varchar(20));
create table orders ( customerNumber char(forty) not cypher distkey sortkey, orderNumber char(twoscore) non null, comments varchar(200), orderDate timestamp, orderType varchar(xx), shipDate timestamp, discount real, quantity integer, productNumber varchar(50));
Upload JSON data to S3
Create an S3 saucepan if y'all don't already have one. If you have installed the AWS client and run aws configure you can do that with aws s3 mkdir. Then re-create the JSON files to S3 like this:
aws s3 cp customers.json s3:/(bucket name) aws s3 cp orders.json s3://(bucket name)
Re-create S3 data into Redshift
Utilize these SQL commands to load the information into Redshift. Some items to notation:
- Utilise the arn cord copied from IAM with the credentials aws_iam_role.
- Yous don't demand to put the region unless your Glue instance is in a unlike Amazon region than your S3 buckets.
- JSON car ways that Redshift will make up one's mind the SQL cavalcade names from the JSON. Otherwise you would accept to create a JSON-to-SQL mapping file.
copy customers from 's3://gluebmcwalkerrowe/customers.json' credentials 'aws_iam_role=arn:aws:iam::xxxxxxx:function/Redshift' region 'eu-west-3' json 'automobile'; copy orders from 's3://gluebmcwalkerrowe/orders.json' credentials 'aws_iam_role=arn:aws:iam::xxxx:role/Redshift' region 'eu-westward-3' json 'auto';
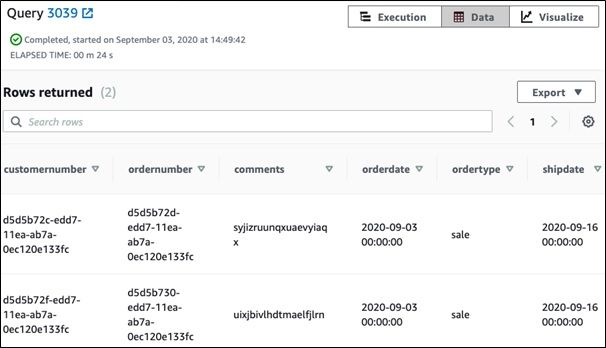
At present you lot tin can run this query:
select * from orders;
And information technology volition produce this output.
Repeat for customer data besides.
Boosted resources
For more than on this topic, explore these resources:
- BMC Machine Learning & Big Data Blog
- AWS Guide, with 15+ articles and tutorials
- Amazon Braket Quantum Calculating: How To Get Started
Learn ML with our free downloadable guide
This e-book teaches machine learning in the simplest style possible. This book is for managers, programmers, directors – and anyone else who wants to learn auto learning. We start with very basic stats and algebra and build upon that.

These postings are my own and practise not necessarily represent BMC'south position, strategies, or stance.
Meet an mistake or take a proffer? Delight permit the states know past emailing blogs@bmc.com.
BMC Bring the A-Game
BMC works with 86% of the Forbes Global l and customers and partners around the world to create their futurity. With our history of innovation, manufacture-leading automation, operations, and service management solutions, combined with unmatched flexibility, we assistance organizations free upward time and space to become an Autonomous Digital Enterprise that conquers the opportunities alee.
Learn more well-nigh BMC ›
Near the writer
![]()
Walker Rowe
Walker Rowe is an American freelancer tech writer and programmer living in Cyprus. He writes tutorials on analytics and big data and specializes in documenting SDKs and APIs. He is the founder of the Hypatia Academy Cyprus, an online schoolhouse to teach secondary school children programming. Y'all can find Walker here and here.
Source: https://www.bmc.com/blogs/amazon-redshift-load-data/
0 Response to "Upload Files to S3 and Load Redshift Etl"
Post a Comment